What are Large Language Models?

What are Large Language Models?
Large language models, also known as LLMs, are very large deep learning models that are pre-trained on vast amounts of data. The underlying transformer is a set of neural networks that consist of an encoder and a decoder with self-attention capabilities. The encoder and decoder extract meanings from a sequence of text and understand the relationships between words and phrases in it.
Transformer LLMs are capable of unsupervised training, although a more precise explanation is that transformers perform self-learning. It is through this process that transformers learn to understand basic grammar, languages, and knowledge.
Unlike earlier recurrent neural networks (RNN) that sequentially process inputs, transformers process entire sequences in parallel. This allows the data scientists to use GPUs for training transformer-based LLMs, significantly reducing the training time.
Transformer neural network architecture allows the use of very large models, often with hundreds of billions of parameters. Such large-scale models can ingest massive amounts of data, often from the internet, but also from sources such as the Common Crawl, which comprises more than 50 billion web pages, and Wikipedia, which has approximately 57 million pages.
Why are large language models important?
Large language models are incredibly flexible. One model can perform completely different tasks such as answering questions, summarizing documents, translating languages and completing sentences. LLMs have the potential to disrupt content creation and the way people use search engines and virtual assistants.
While not perfect, LLMs are demonstrating a remarkable ability to make predictions based on a relatively small number of prompts or inputs. LLMs can be used for generative AI (artificial intelligence) to produce content based on input prompts in human language.
LLMs are big, very big. They can consider billions of parameters and have many possible uses. Here are some examples:
-Open AI's GPT-3 model has 175 billion parameters. Its cousin, ChatGPT, can identify patterns from data and generate natural and readable output. While we don’t know the size of Claude 2, it can take inputs up to 100K tokens in each prompt, which means it can work over hundreds of pages of technical documentation or even an entire book.
-AI21 Labs’ Jurassic-1 model has 178 billion parameters and a token vocabulary of 250,000-word parts and similar conversational capabilities.
Cohere’s Command model has similar capabilities and can work in more than 100 different languages.
-LightOn's Paradigm offers foundation models with claimed capabilities that exceed those of GPT-3. All these LLMs come with APIs that allow developers to create unique generative AI applications.
How do large language models work?
A key factor in how LLMs work is the way they represent words. Earlier forms of machine learning used a numerical table to represent each word. But, this form of representation could not recognize relationships between words such as words with similar meanings. This limitation was overcome by using multi-dimensional vectors, commonly referred to as word embeddings, to represent words so that words with similar contextual meanings or other relationships are close to each other in the vector space.
Using word embeddings, transformers can pre-process text as numerical representations through the encoder and understand the context of words and phrases with similar meanings as well as other relationships between words such as parts of speech. It is then possible for LLMs to apply this knowledge of the language through the decoder to produce a unique output.
What are applications of large language models?
There are many practical applications for LLMs.
Copywriting
Apart from GPT-3 and ChatGPT, Claude, Llama 2, Cohere Command, and Jurassiccan write original copy. AI21 Wordspice suggests changes to original sentences to improve style and voice.
Knowledge base answering
Often referred to as knowledge-intensive natural language processing (KI-NLP), the technique refers to LLMs that can answer specific questions from information help in digital archives. An example is the ability of AI21 Studio playground to answer general knowledge questions.
Text classification
Using clustering, LLMs can classify text with similar meanings or sentiments. Uses include measuring customer sentiment, determining the relationship between texts, and document search.
Code generation
LLM are proficient in code generation from natural language prompts. Amazon Q Developer can code in Python, JavaScript, Ruby and several other programming languages. Other coding applications include creating SQL queries, writing shell commands and website design.
Text generation
Similar to code generation, text generation can complete incomplete sentences, write product documentation or, like Alexa Create, write a short children's story.
How are large language models trained?
Transformer-based neural networks are very large. These networks contain multiple nodes and layers. Each node in a layer has connections to all nodes in the subsequent layer, each of which has a weight and a bias. Weights and biases along with embeddings are known as model parameters. Large transformer-based neural networks can have billions and billions of parameters. The size of the model is generally determined by an empirical relationship between the model size, the number of parameters, and the size of the training data.
Training is performed using a large corpus of high-quality data. During training, the model iteratively adjusts parameter values until the model correctly predicts the next token from an the previous squence of input tokens. It does this through self-learning techniques which teach the model to adjust parameters to maximize the likelihood of the next tokens in the training examples.
Once trained, LLMs can be readily adapted to perform multiple tasks using relatively small sets of supervised data, a process known as fine tuning.
Three common learning models exist:
Zero-shot learning; Base LLMs can respond to a broad range of requests without explicit training, often through prompts, although answer accuracy varies.
Few-shot learning: By providing a few relevant training examples, base model performance significantly improves in that specific area.
Fine-tuning: This is an extension of few-shot learning in that data scientists train a base model to adjust its parameters with additional data relevant to the specific application.
What is the future of LLMs?
The introduction of large language models like ChatGPT, Claude 2, and Llama 2 that can answer questions and generate text points to exciting possibilities in the future. Slowly, but surely, LLMs are moving closer to human-like performance. The immediate success of these LLMs demonstrates a keen interest in robotic-type LLMs that emulate and, in some contexts, outperform the human brain. Here are some thoughts on the future of LLMs,
Increased capabilities
As impressive as they are, the current level of technology is not perfect and LLMs are not infallible. However, newer releases will have improved accuracy and enhanced capabilities as developers learn how to improve their performance while reducing bias and eliminating incorrect answers.
Audiovisual training
While developers train most LLMs using text, some have started training models using video and audio input. This form of training should lead to faster model development and open up new possibilities in terms of using LLMs for autonomous vehicles.
Workplace transformation
LLMs are a disruptive factor that will change the workplace. LLMs will likely reduce monotonous and repetitive tasks in the same way that robots did for repetitive manufacturing tasks. Possibilities include repetitive clerical tasks, customer service chatbots, and simple automated copywriting.
Conversational AI
LLMs will undoubtedly improve the performance of automated virtual assistants like Alexa, Google Assistant, and Siri. They will be better able to interpret user intent and respond to sophisticated commands.
How can AWS help with LLMs?
AWS offers several possibilities for large language model developers. Amazon Bedrock is the easiest way to build and scale generative AI applications with LLMs. Amazon Bedrock is a fully managed service that makes LLMs from Amazon and leading AI startups available through an API, so you can choose from various LLMs to find the model that's best suited for your use case.
Amazon SageMaker JumpStart is a machine learning hub with foundation models, built-in algorithms, and prebuilt ML solutions that you can deploy with just a few clicks With SageMaker JumpStart, you can access pretrained models, including foundation models, to perform tasks like article summarization and image generation. Pretrained models are fully customizable for your use case with your data, and you can easily deploy them into production with the user interface or SDK.
Vous aimrez peut-etre

Natural Language Processing (NLP)What is Natural Language Processing?Natural Language Processing (NL.....
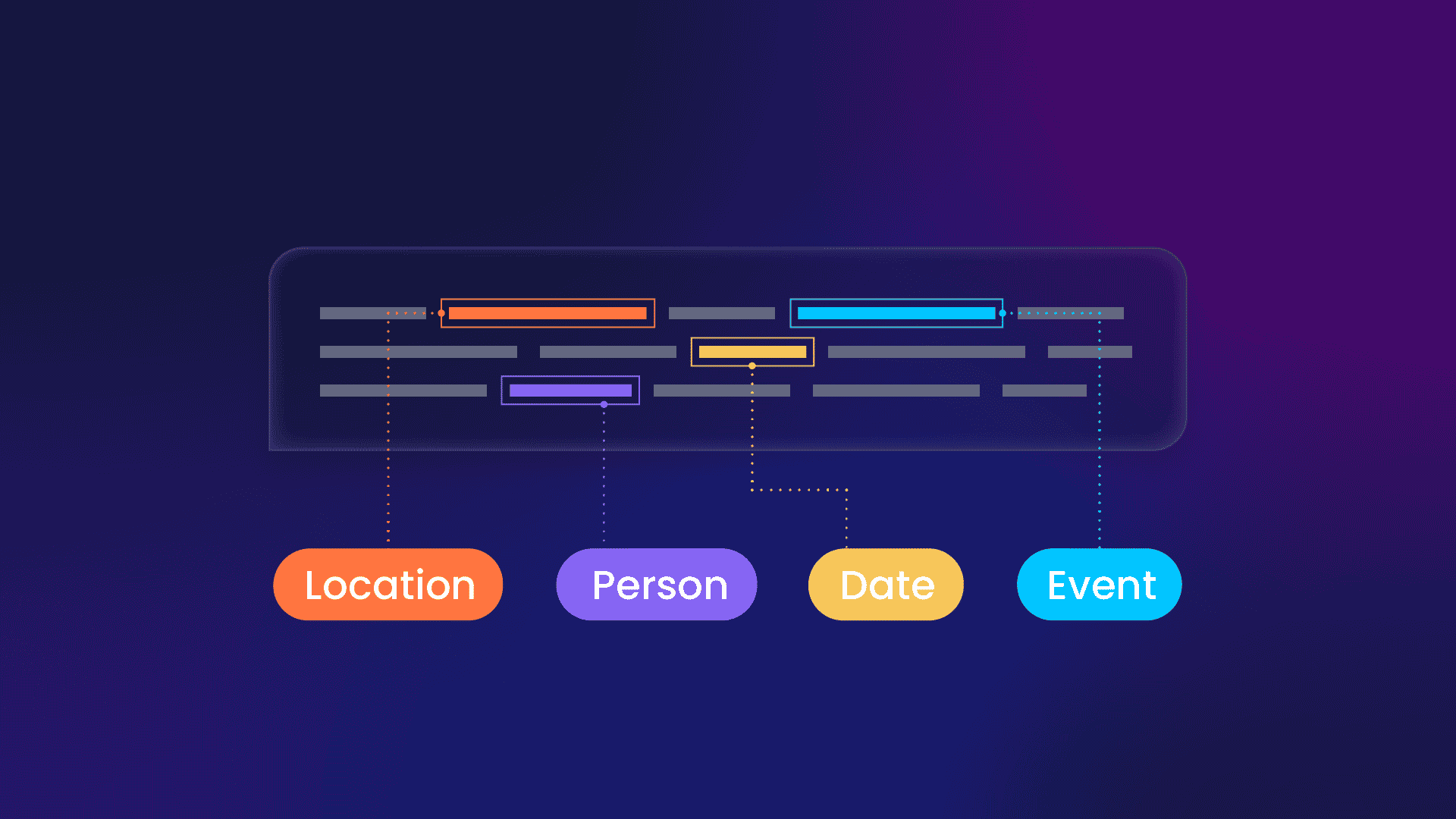
Named Entity Recognition (NER) Named Entity Recognition (NER) Named Enti.....